Custom built versus general purpose data management tools
Recently I have been discussing a DH project with a PI who told me that their department was debating if several projects that are being discussed should be developed and implemented separately. The alternative was creating a general tool to address the needs of the current projects which will hopefully be ready for additional future projects.
There is indeed tension between spending money and other resources on software (a database web application) that is going to serve only one research project, versus a general-purpose tool. The idea of a general-purpose tool, with a scope limited to collecting, organizing, presenting and reporting on a reasonably complex data model seems on the face of it quite appealing and sensible.
The problems with the general tool approach are:
- Collecting, refining and specifying the requirements for a general tool will likely take longer than building a project specific tool will take. This is made harder by the fact that the specification will always be a moving target, based on current or planned research projects. The costs associated with building such a general package will also be on a different, much larger order of magnitude then for a project-specific tool.
- Additionally, the most intensive and careful specification will not create a truly universal, ready-to-implement-with-no-modification tool. There will always be an added feature, a bit of functionality to change, a required configuration of something that was initially designed as constant. An example may be that image management capabilities using IIIF and mirador may need to be added to a database application dealing with manuscripts.
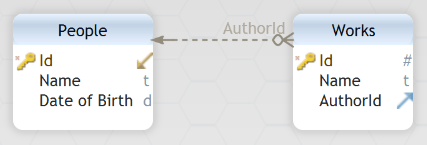
- Probably the biggest hurdle is that as was demonstrated in a previous post, the data model of a DH project can be relatively complex, and a general-purpose tool will need to have an interface for a non-programmer to specify the tables, columns, primary and foreign keys as well as data types and indices. Furthermore, the tool will need to be able to automatically generate the interface for a custom data model. This requirement alone, although technically possible, puts the price of such a tool beyond what makes sense for most academic institutions.
The almost certain need for modifications of / additions to a general-purpose application, result in another big drawback of developing such a system in an academic setting – the need to retain the knowledge and expertise for such on-going development, in essence maintaining the capabilities of a software development group dedicated to the tool.
General purpose information management systems for DH do exist. Examples include Nodegoat and Heurist. These are capable solutions but going beyond data management will require considerable modification and customization. Pricing in the case of Heurist is not entirely clear, and Nodegoat requires an annual fee for a publicly available site.
A future post will present a complete, robust and almost free-to-run cloud-based framework for developing such projects.