
DH-Dev Blog
Recently I have been discussing a DH project with a PI who told me that their department was debating if several projects that are being discussed should be developed and implemented separately. The alternative was creating a general tool to address the needs of the current projects which will hopefully be ready for additional future projects. There is indeed tension between spending money and other resources on software (a database web application) that is going to serve only one research project, versus a general-purpose tool. The idea of a general-purpose tool, with a scope limited to collecting, organizing, presenting and reporting on a reasonably complex data model seems on the face of it quite appealing and sensible. The problems with the general tool approach are: Collecting, refining and specifying the requirements for a general tool will likely take longer than building a project specific tool will take. This is made harder by the fact that the specification will always be a moving target, based on current or planned research projects. The costs associated with building such a general package will also be on a different, much larger order of magnitude then for a project-specific tool. Additionally, the most intensive and careful specification will not create a truly universal, ready-to-implement-with-no-modification tool. There will always be an added feature, a bit of functionality to change, a required configuration of something that was initially designed as constant. An example may be that image management capabilities using IIIF and mirador may need to be added to a database application dealing with manuscripts. Probably the biggest hurdle is that as was demonstrated in a previous post, the data model of a DH project can be relatively complex, and a general-purpose tool will need to have an interface for a non-programmer to specify the tables, columns, primary and foreign keys as well as data types and indices. Furthermore, the tool will need to be able to automatically generate the interface for a custom data model. This requirement alone, although technically possible, puts the price of such a tool beyond what makes sense for most academic institutions. The almost certain need for modifications of / additions to a general-purpose application, result in another big drawback of developing such a system in an academic setting – the need to retain the knowledge and expertise for such on-going development, in essence maintaining the capabilities of a software development group dedicated to the tool. General purpose information management systems for DH do exist. Examples include Nodegoat and Heurist . These are capable solutions but going beyond data management will require considerable modification and customization. Pricing in the case of Heurist is not entirely clear, and Nodegoat requires an annual fee for a publicly available site. A future post will present a complete, robust and almost free-to-run cloud-based framework for developing such projects.
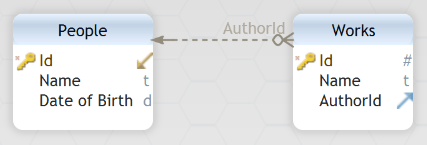
In a previous post, I discussed the challenges of collecting data in one or more spreadsheets. A defining characteristic of a spreadsheet in this context is usually that it is a single table containing information about many types of objects (people, places, works, events for example). Another characteristic is that relationships between these objects are defined by being on a single line in the spreadsheet. So to say person A is an associate of person B, his name will need to be in a column named Associate (maybe Associate1 or 2 etc.) where person B’s name is in an another column such as Author on that same row. If person A is also person B’s sibling his name will need to be in an additional column. Because the only way to connect between objects is to put them on the same row, the work’s name will also need to be on the Author’s table row, as seen below.
This is a post aimed at people who need to deal with organizing, investigating, saving and retrieving information, but who have little or no knowledge and experience of how to do this effectively. A data oriented Digital Humanities project is often started in a spreadsheet. More and more columns are added as new options are found – for example a Location column was created in a table of manuscripts but suddenly it is not enough as the manuscript may have moved between cities. The quick solution to this will be to enter a list of values separated by some delimiter (location1; location2; …). An alternative may be to split Location into Location1 and Location2, and later Location3 and 4 are added and may still not be enough. Because location name spelling may have changed through time, a city will appear in the various columns in several variants – and don’t let us forget spelling mistakes. A single table becomes even more gnarly when people can appear as authors of a work but also as collaborators (Colab1, Colba2 etc.). Some columns will require an accuracy description, such as dates, and some an indication of certainty in the assertions represented by that column’s data. Major problems with this approach arise because a large part of the data is repeated, and needs to be repeated accurately or it will not be available for aggregation and summation. Maintenance and changes to the data are complex and unreliable as changes to a data point need to be performed with a search and replace operation across all columns, or even worse, in all lists where the data may occur. More specific changes are even harder to make reliably – in the manuscript locations example above, let’s assume the order of locations in the list represents the order in which the manuscript traveled between locations, so to change the order will require editing the list. Additionally, complex relationships between entities are difficult to represent and even harder to investigate and retrieve. The other question that presents itself quickly is where will the data live, who will be able to look at it, query and report on it and who and how will be able to maintain and update it. Although google sheets and even excel workbooks can be shared over the web, they are clearly insufficient in terms of presentation, access control and complex data structure capabilities. The required solution is a database web application. A future post will present a complete, robust and almost free-to-run framework for such projects. The database component in a database web application can take several forms. A relational database is usually selected for data structures similar to those outlined above. The term SQL (Structured Query Language) which is the name of a general-purpose language used to deal with relational data is often used for this approach too. Common relational database systems include MySQL, Postgres, SQLServer as well as others. The next post will describe the relational data modeling solutions for some of the challenges outlined above.
It is quite common to think about technology as something that is waiting to be built, like a sculpture is waiting to be chiseled out of a chunk of marble. Another, somewhat opposing picture people sometimes have is of a house already there just waiting to be moved into, with all the utilities just in place to be plugged into. These two views correspond to ways people in the Humanities (researchers, administrators, grad students sometimes) expect technology can be used in their projects and work. I should add that these conceptions of technology are not uncommon in business either. The sculpture waiting in the chunk of marble corresponds to the expectation that the idea can be brought into existence just by describing it in broad terms, something like – I want something on the internet where I can collect my data, get summaries and reports and draw graphs with the results, but I’m not sure what the data will be or how the research questions will be formed. Oh and I want my grad students to be able to add the data from home and also the data we are collecting may change in six months. The idea of a house or office building just waiting to be moved into corresponds to the question – how come there isn’t software that does exactly what I need? And in a time when so much software is being made, it seems like the expectation is valid. But if we stretch this analogy and think about what it takes to erect a building the challenge becomes clearer. The process starts with architecture – fitting form to function and selecting the building method – multi-person team or a single part time builder. Then there is connecting the utilities – using mapping services from here and image management from there. Securing the building from external threats as well as from mishaps children (inexperienced users) can have on the stairs is of utmost importance. Allowing and managing sub-leasing of the space (collaborators adding to the data or making other uses of it) can be a requirement and last but not least - performing on-going maintenance (fixing bugs), complying with changing city code (new web standards and browsers) and applying a fresh coat of paint (new look and feel to the web site) once in a while, must be planned for. So the technology to be used in a Digital Humanities project will not spring into being by simply talking about it – it will require a careful specification of requirements and of use cases, and a good fit between the way it is built and ways it will be used and maintained. In specific cases, software packages can be found to perform certain parts of the tasks at hand but it will often be the case that some bespoke software will be needed to fulfill the project’s goals in a sustainable way. The balancing act between custom built project software and a general-purpose system will be discussed (maybe…) in a future post.