
Relationships - the relational database solution to complex data structures
In a previous post, I discussed the challenges of collecting data in one or more spreadsheets. A defining characteristic of a spreadsheet in this context is usually that it is a single table containing information about many types of objects (people, places, works, events for example). Another characteristic is that relationships between these objects are defined by being on a single line in the spreadsheet. So to say person A is an associate of person B, his name will need to be in a column named Associate (maybe Associate1 or 2 etc.) where person B’s name is in an another column such as Author on that same row. If person A is also person B’s sibling his name will need to be in an additional column. Because the only way to connect between objects is to put them on the same row, the work’s name will also need to be on the Author’s table row, as seen below.
| Author | Work | Associate1 | Associate2 | Sibling1 | Sibling2 |
|---|---|---|---|---|---|
| PersonB | Book Name | PersonA | PersonC | PersonA |
Relational data modeling uses an approach called reaching normal form. A good description of the normal form rules can be found here for example. I like to think of somewhat simpler rules:
- Each piece of information is included only once in the database.
- Each object type is in a separate table, such as tables for people, places, works, events.
- Each table cell has one data value – never use delimited lists.
- Each row in each table has a (usually integer) identifying value, called the Primary Key (PK), unique to this table, and not carrying additional information. So never use the person’s name as the PK for the persons table – the obvious reason being that it may not be unique, but also because as we will see, the PK of a table can and will be repeated in other tables.
- Relationships between objects of different types are represented by one of the following:
- Foreign Keys (FKs). A foreign key is a column in one table, containing PK values from another table. FKs are used for a one-to-many relationship (see below).
- A junction table with two or more columns containing PK values from the two tables a many-to-many relationship (see below) exists between.
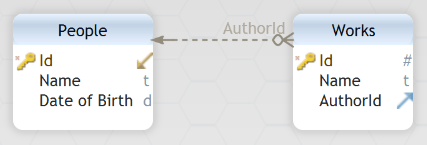
A one-to-many relationship is demonstrated in the previous simplified diagram where we show tables for people and for works. The author of a work is indicated by the AuthorId column in the works table, which will have the Id of someone from the people table, not their name. The AuthorId column is an FK on the Works table. This is a one-to-many relationship because a work has a single author (in this scenario) but a person can be the author of many works. The authors’ name is only included once in the database (first rule) although they may have authored many works. People and works are in separate tables (second rule), and the PK of the People table is independent of additional information (fourth rule).

This diagram shows a many-to-many relationship between the works and people tables, implementing the possibility of having an author and collaborators on a certain work, as was indicated in the spreadsheet above. The PeopleAndWorks table is a junction table in which there will be a row for each relationship between a work and a person. The type of the relationship, be it author or collaborator, is indicated with an FK to an additional table, the RelationshipTypes table. This fourth table makes it easy to add a new relationship type, Editor for example, a change that in the spreadsheet would require the addition of a column.
In the spreadsheet example above, another type of a relationship is included, that of a sibling. This is a case of a many-to-many relationship between a table (People) and itself. Designing a junction table to capture this is left to the reader…
This post is an extremely abbreviated description of relational data modeling principles. Further reading is recommended and I can try and address specific questions in the comments.